1 Introduction à R
1.1 Introduction
R est à la fois un langage de programmation et un logiciel de calcul statistique. Il est gratuit et libre (open-source). Pour commencer, vous allez devoir installer deux logiciels :
R, le language de programmation lui même.- Sélectionnez votre système d’exploitation et choisissez la version la plus récente de
R
- Sélectionnez votre système d’exploitation et choisissez la version la plus récente de
- RStudio, une excellente interface de programmation pour
R.- Attention, il faut que vous ayez installé
Rpour pouvoir utiliser RStudio. RStudio est juste une interface permettant d’utiliserR.
- Attention, il faut que vous ayez installé
Les éditeurs du logiciel RStudio ont par ailleurs crée la plate-forme en ligne RStudio Cloud rstudio.cloud.. Cette dernière permet d’utiliser R en ligne depuis son navigateur, de faire des tutoriels d’introduction (voire plus avancés), etc. Afin de vous familiariser au plus vite avec le R et R Studio (pour ceux qui ne connaissent pas déjà R), il faut au plus vite que
Vous vous rendiez sur rstudio.cloud. et que vous vous y créiez un compte (Sign Up). La plateforme est en anglais mais ça devrait être compréhensible
Une fois votre compté crée, allez sur la page des Primers (tutoriels d’introduction) : https://rstudio.cloud/learn/primers, et effectuez au minimum les tutoriels “The Basics” et “Work with Data”. Idéalement effectuez aussi “Visualize Data” et “Tidy Your Data”. Les plus courageux/motivés pourront également effectuer “Iterate” et “Write Functions”.
R Studio Cloud vous permet également d’utiliser R en ligne depuis un navigateur sans avoir à l’installer sur votre machine. C’est extrêmement pratique, mais la version gratuite ne permet que 15 heures d’utilisation par mois pour chaque compte. Son utilisation sera donc réservée aux éventuels cours dans une salle informatique et pour ceux d’entre vous qui sont dans l’impossibilité d’installer R sur leur ordinateur.
1.2 Démarrer R et R Studio
Il est fondamental de comprendre la différence entre R, le langage de programmation, et RStudio, l’interface pour R qui vous permet de travailler efficacement (et plus facilement) avec R.
La meilleure façon de comprendre l’utilité de RStudio est de commencer par R sans RStudio. Pour ce faire, double-clickez sur le programme R que vous devriez avoir installé sur votre ordinateur en suivant les instructions ci-dessus (sous windows ou Mac), ou lancez R depuis votre terminal (sous Linux ou Mac) en tapant R dans un terminal, voir 1.2. Vous venez d’ouvrir la console R qui vous permet de commencer à taper du code juste après le symbole >, appelé prompt. Essayez de taper 2 + 2 or print("Votre Nom") puis appuyez sur la touche Entrée. Et voilà, votre première commande R

Figure 1.1: Le logo de R
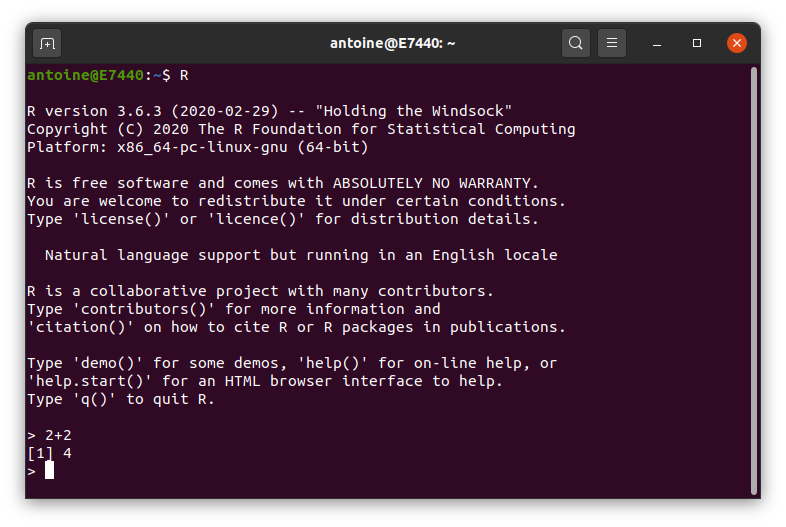
Figure 1.2: Un terminal R sous Linux
Taper une commande après l’autre dans la console n’est pas très pratique au fur et à mesure que notre analyse devient plus complexe. L’idéal serait de rassembler toutes les instructions de commande dans un fichier et de les exécuter l’une après l’autre, automatiquement. Nous pouvons le faire en écrivant des fichiers dits script , c’est-à-dire de simples fichiers texte avec l’extension .R ou .r qui peuvent être insérés (ou sourcés) dans une session R. RStudio rend ce processus très simple.
Ouvrez RStudio en cliquant sur l’application RStudio sur votre ordinateur, et remarquez à quel point l’environnement entier est différent de la console R de base - en fait, cette console R fonctionne dans votre panneau inférieur gauche. Le panneau supérieur gauche est un espace où vous pouvez écrire des scripts, c’est-à-dire de nombreuses lignes de codes que vous pouvez exécuter quand vous le souhaitez. Pour exécuter une seule ligne de code, il suffit de la mettre en surbrillance et d’appuyer sur “Ctrl” + “Entrée”.
RStudio dispose d’un grand nombre de raccourcis clavier utiles. Une liste de ceux-ci peut être trouvée en utilisant un raccourci clavier – le raccourci clavier qui permet de tous les utiliser :
- Sous Windows ou linux:
Alt+Shift+K - Sous Mac:
Option+Shift+K
L’équipe de R Studio a développé [un certain nombre de “cheatsheets”] (https://www.rstudio.com/resources/cheatsheets/) pour travailler à la fois avec R et R Studio. Cette fiche sur la base R (http://www.rstudio.com/wp-content/uploads/2016/05/base-r.pdf) résume un grand nombre des concepts de ce document.
1.2.1 Un premier glossaire
R: un langage de programmation statistiqueR Studio: un environnement de développement intégré (IDE) pour travailler avecR.- commande : saisie de l’utilisateur (texte ou chiffres) que
Rcomprend. - script : une liste de commandes rassemblées dans un fichier texte, chacune étant séparée par une nouvelle ligne, à exécuter l’une après l’autre.
1.3 Calculs de base
Pour commencer, nous utiliserons le R comme une simple calculatrice. Exécutez le code suivant soit directement depuis votre console RStudio, soit dans RStudio en l’écrivant dans un script et en l’exécutant en utilisant “Ctrl” + “Entrée”.
Addition, Sousraction, Multiplication et Division
| Math | code R |
Résultat |
|---|---|---|
| \(3 + 2\) | 3 + 2 |
5 |
| \(3 - 2\) | 3 - 2 |
1 |
| \(3 \cdot2\) | 3 * 2 |
6 |
| \(3 / 2\) | 3 / 2 |
1.5 |
Exposants
| Math | code R |
Résultat |
|---|---|---|
| \(3^2\) | 3 ^ 2 |
9 |
| \(2^{(-3)}\) | 2 ^ (-3) |
0.125 |
| \(100^{1/2}\) | 100 ^ (1 / 2) |
10 |
| \(\sqrt{100}\) | sqrt(100) |
10 |
Constantes mathématiques
| Math | code R |
Résultat |
|---|---|---|
| \(\pi\) | pi |
3.1415927 |
| \(e\) | exp(1) |
2.7182818 |
Logarithmes
Notez que nous utiliserons \(\ln\) et \(\log\) de manière interchangeable pour désigner le logarithme naturel. Il n’y a pas de ln() dans R, mais on utilise log() pour désigner le logarithme naturel.
| Math | code R |
Résultat |
|---|---|---|
| \(\log(e)\) | log(exp(1)) |
1 |
| \(\log_{10}(1000)\) | log10(1000) |
3 |
| \(\log_{2}(8)\) | log2(8) |
3 |
| \(\log_{4}(16)\) | log(16, base = 4) |
2 |
Trigonometrie
| Math | code R |
Résultat |
|---|---|---|
| \(\sin(\pi / 2)\) | sin(pi / 2) |
1 |
| \(\cos(0)\) | cos(0) |
1 |
1.4 Obtenir de l’aide
En utilisant R comme calculatrice, nous avons vu un certain nombre de fonctions : sqrt(), exp(), log() et sin(). Pour obtenir de la documentation sur une fonction dans R, il suffit de mettre un point d’interrogation devant le nom de la fonction, ou d’appeler la fonction help(function) et RStudio affichera la documentation, par exemple :
?log
?sin
?paste
?lm
help(lm) # help() est équivalent
help(ggplot,package="ggplot2") # affiche l'aide d'un package donnéSouvent, l’une des choses les plus difficiles à faire quand on apprend R est de demander de l’aide. D’abord, vous devez décider de demander de l’aide, puis vous devez savoir comment demander de l’aide. Votre toute première ligne de défense devrait être de rechercher sur Google votre message d’erreur ou une brève description de votre problème. (La capacité à résoudre des problèmes à l’aide de cette méthode devient rapidement une compétence extrêmement précieuse). Si cela échoue, et cela finira par arriver, vous devriez demander de l’aide. Il y a un certain nombre de choses que vous devez inclure lorsque vous contactez un enseignant ou que vous postez sur un site d’aide tel que [Stack Overflow] (https://stackoverflow.com).
- Décrivez ce que vous attendez du code.
- Indiquez l’objectif final que vous essayez d’atteindre. (Parfois, ce que vous attendez du code n’est pas ce que vous voulez réellement faire).
- Fournissez le texte intégral de toutes les erreurs que vous avez reçues.
- Fournissez suffisamment de code pour recréer l’erreur.
- Parfois, il est également utile d’inclure une capture d’écran de toute votre fenêtre RStudio lorsque l’erreur se produit.
Si vous suivez ces étapes, votre problème sera résolu beaucoup plus rapidement, et vous en apprendrez peut-être plus au cours du processus. Ne vous découragez pas en rencontrant des erreurs et des difficultés lors de l’apprentissage de R". (Ou toute autre compétence technique.) Cela fait tout simplement partie du processus d’apprentissage.
1.5 Installation de packages
R est livré avec un certain nombre de fonctions et d’ensembles de données intégrés, mais l’une des principales forces de R en tant que projet open-source est son système de paquets (packages). Les paquets ajoutent des fonctions et des données supplémentaires. Souvent, si vous voulez faire quelque chose dans R, et que ce n’est pas disponible par défaut, il y a de fortes chances qu’il existe un paquet qui répondra à vos besoins.
Pour installer un paquet, utilisez la fonction install.packages(). Imaginez que vous achetez un livre de recettes au magasin, que vous le rapportez à la maison et que vous le mettez sur votre étagère (c’est-à-dire dans votre bibliothèque) :
install.packages("ggplot2")Une fois qu’un paquet est installé, il doit être chargé dans votre session R avant d’être utilisé. Cela revient à retirer le livre de l’étagère et à l’ouvrir pour le lire.
library(ggplot2)Une fois que vous fermez R, tous les paquets sont fermés et remis sur l’étagère imaginaire. La prochaine fois que vous ouvrirez R, vous n’aurez pas à réinstaller le paquet, mais vous devrez charger tous les paquets que vous avez l’intention d’utiliser en invoquant library().
1.6 Code et sortie dans ce document
Pour distinguer visuellement le code R de sa sortie, toutes le lignes de sortie commencent par ##. Un bout de code typique avec sa sortie va ressembler à ça :
1 + 3 ## [1] 4# tout ce qui se situe après un # est un commentaire, R ne l'exécute pasoù vous voyez sur la première ligne le code R, et sur la deuxième ligne la sortie. Comme mentionné, cette ligne commence par ## pour dire c’est une sortie, suivi par [1] (indiquant qu’il s’agit d’un vecteur de longueur un - plus d’informations ci-dessous !), suivi par le résultat réel - 1 + 3 = 4 !
Notez que vous pouvez simplement copier et coller tout le code que vous voyez dans votre console R. En fait, vous êtes fortement encouragé à le faire et à essayer tout le code que vous voyez dans ce livre.
1.7 Types de données
R a un certain nombre de types de données de base. Il est utile de savoir quels types de données sont à votre disposition :
- Numérique
- Aussi connu sous le nom de Double. Le type par défaut lorsqu’il s’agit de chiffres.
- Exemples :
1,1.0,42.5
- Entier
- Exemples :
1L,2L,42L.
- Exemples :
- Complexe
- Exemple :
4 + 2i.
- Exemple :
- Logique
- Deux valeurs possibles :
TRUEetFALSE - Vous pouvez également utiliser les lettres
TetF, mais cela n’est pas recommandé. NAest également considéré comme logique.
- Deux valeurs possibles :
- Caractère
- Exemples :
"a","Statistiques","1 plus 2".
- Exemples :
- Catégorique ou
factor.- Un mélange d’entier et de caractère. Une variable
factorattribue un label à une valeur numérique. - Par exemple,
factor(x=c(0,1),labels=c("homme", "femme"))assigne la chaîne homme aux valeurs numériques0, et la chaîne femme à la valeur1.
- Un mélange d’entier et de caractère. Une variable
1.8 Structures de données
| Dimension | Homogène | Hétérogène |
|---|---|---|
| 1 | Vector | List |
| 2 | Matrix | Data Frame |
| 3+ | Array | nested Lists |
1.8.1 Vecteurs
De nombreuses opérations en R font un usage intensif de vecteurs. Un vecteur est un conteneur pour les objets de type identique (voir 1.7 ci-dessus). Les vecteurs dans R sont indexés à partir de 1. C’est ce que le [1] dans la sortie indique, que le premier élément de la ligne affichée est le premier élément du vecteur. Les plus grands vecteurs afficheront des lignes supplémentaires avec quelque chose comme [7] où 7 est l’indice du premier élément de cette ligne.
La façon la plus courante de créer un vecteur en R est sans doute d’utiliser la fonction c(), qui est l’abréviation de “combine”. Comme son nom l’indique, elle combine une liste d’éléments séparés par des virgules.
c(1, 3, 5, 7, 8, 9)## [1] 1 3 5 7 8 9Ici, R produit simplement ce vecteur. Si nous voulons stocker ce vecteur dans une variable, nous pouvons le faire avec l’opérateur assignation <-. Dans ce cas, la variable x contient maintenant le vecteur que nous venons de créer, et nous pouvons accéder au vecteur en tapant x.
x <- c(1, 3, 5, 7, 8, 9)
x## [1] 1 3 5 7 8 9Parce que les vecteurs doivent contenir des éléments qui sont tous du même type, R va automatiquement coercer (c’est-à-dire convertir) vers un seul type lorsqu’on essaie de créer un vecteur qui combine plusieurs types.
c(42, "Statistiques", TRUE)## [1] "42" "Statistiques" "TRUE"c(42, TRUE)## [1] 42 1Il est fréquent que vous souhaitiez créer un vecteur basé sur une séquence de nombres. La façon la plus rapide et la plus simple de le faire est d’utiliser l’opérateur :, qui crée une séquence d’entiers entre deux entiers spécifiés.
(y <- 1:100)## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
## [19] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
## [37] 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54
## [55] 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
## [73] 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
## [91] 91 92 93 94 95 96 97 98 99 100Ici, nous voyons R marquer les lignes après la première, car il s’agit d’un grand vecteur. Nous voyons également qu’en mettant des parenthèses autour de l’affectation, R stocke le vecteur dans une variable appelée y et sort automatiquement y vers la console.
Notez que les scalaires n’existent pas dans R. Ce sont simplement des vecteurs de longueur 1.
2## [1] 2Si nous voulons créer une séquence qui ne soit pas limitée aux nombres entiers et qui augmente de 1 à la fois, nous pouvons utiliser la fonction seq().
seq(from = 1.5, to = 4.2, by = 0.1)## [1] 1.5 1.6 1.7 1.8 1.9 2.0 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 3.0 3.1 3.2 3.3
## [20] 3.4 3.5 3.6 3.7 3.8 3.9 4.0 4.1 4.2Nous discuterons des fonctions en détail plus tard, mais notez ici que les étiquettes d’entrée “from”, “to” et “by” sont facultatives.
seq(1.5, 4.2, 0.1)## [1] 1.5 1.6 1.7 1.8 1.9 2.0 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 3.0 3.1 3.2 3.3
## [20] 3.4 3.5 3.6 3.7 3.8 3.9 4.0 4.1 4.2Une autre opération courante pour créer un vecteur est rep(), qui peut répéter une seule valeur un certain nombre de fois.
rep("A", times = 10)## [1] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"La fonction rep() peut être utilisée pour répéter un vecteur un certain nombre de fois.
rep(x, times = 3)## [1] 1 3 5 7 8 9 1 3 5 7 8 9 1 3 5 7 8 9Nous avons maintenant vu quatre façons différentes de créer des vecteurs :
c():seq()rep()
Jusqu’à présent, nous les avons surtout utilisés de manière isolée, mais ils sont souvent utilisés ensemble.
c(x, rep(seq(1, 9, 2), 3), c(1, 2, 3), 42, 2:4)## [1] 1 3 5 7 8 9 1 3 5 7 9 1 3 5 7 9 1 3 5 7 9 1 2 3 42
## [26] 2 3 4La longueur d’un vecteur peut être obtenue avec la fonction length().
length(x)## [1] 6length(y)## [1] 1001.8.1.1 Exercice 1
- Créer un vecteur de cinq uns, c’est-à-dire
[1,1,1,1,1,1]. - Remarquez que l’opérateur deux-points
a:best juste l’abréviation de construire une séquence deaàb. Créez un vecteur dont le compte à rebours est de 10 à 0, c’est-à-dire qu’il ressemble à[10,9,8,7,6,5,4,3,2,1,0]! - la fonction
repprend des arguments supplémentairestimes(comme ci-dessus), eteach, qui vous indique combien de fois chaque élément doit être répété (par opposition au vecteur d’entrée entier). Utilisezreppour créer un vecteur qui ressemble à ceci :[1 1 1 2 2 2 3 3 3 1 1 1 2 2 2 3 3 3]
1.8.1.2 Extraire des sous-vecteurs
Pour extraire un sous-vecteur (subsetting), c’est-à-dire pour n’en choisir que certains éléments, nous utilisons des crochets, “[]”. Nous voyons ici que x[1] renvoie le premier élément, et x[3] renvoie le troisième élément :
x## [1] 1 3 5 7 8 9x[1]## [1] 1x[3]## [1] 5Nous pouvons également exclure certains indices, dans ce cas le deuxième élément.
x[-2]## [1] 1 5 7 8 9Enfin, nous voyons que nous pouvons faire des sous-ensembles sur la base d’un vecteur d’indices.
x[1:3]## [1] 1 3 5x[c(1,3,4)]## [1] 1 5 7Tous les éléments ci-dessus sont des sous-ensembles d’un vecteur utilisant un vecteur d’indices. (Rappelez-vous qu’un seul nombre reste un vecteur) Nous pourrions plutôt utiliser un vecteur de valeurs logiques.
z = c(TRUE, TRUE, FALSE, TRUE, TRUE, FALSE)
z## [1] TRUE TRUE FALSE TRUE TRUE FALSEx[z]## [1] 1 3 7 8R est capable d’effectuer de nombreuses opérations sur les vecteurs et les scalaires :
x = 1:10 # un vecteur
x + 1 # ajouter un scalaire## [1] 2 3 4 5 6 7 8 9 10 112 * x # multiplier tous les éléments par 2## [1] 2 4 6 8 10 12 14 16 18 202 ^ x # calculer 2 exposant x ## [1] 2 4 8 16 32 64 128 256 512 1024sqrt(x) # calcule la racine carrée de tous les éléments de x## [1] 1.000000 1.414214 1.732051 2.000000 2.236068 2.449490 2.645751 2.828427
## [9] 3.000000 3.162278log(x) # prend le log naturel de tous les éléments en x## [1] 0.0000000 0.6931472 1.0986123 1.3862944 1.6094379 1.7917595 1.9459101
## [8] 2.0794415 2.1972246 2.3025851x + 2*x # ajouter le vecteur x au vecteur 2x## [1] 3 6 9 12 15 18 21 24 27 30Nous voyons que lorsqu’une fonction comme log() est utilisée sur un vecteur x, un vecteur est renvoyé qui a appliqué la fonction à chaque élément du vecteur x.
1.8.2 Opérateurs logiques
| Opérateur | Résumé | Exemple | Résultat |
|---|---|---|---|
x < y |
x plus petit que y |
3 < 42 |
TRUE |
x > y |
x plus grand que y |
3 > 42 |
FALSE |
x <= y |
x plus petit ou égal à y |
3 <= 42 |
TRUE |
x >= y |
x plus grand ou égal à y |
3 >= 42 |
FALSE |
x == y |
x égal à y |
3 == 42 |
FALSE |
x != y |
x pas égal à y |
3 != 42 |
TRUE |
!x |
pas x |
!(3 > 42) |
TRUE |
x | y |
x ou y |
(3 > 42) | TRUE |
TRUE |
x & y |
x et y |
(3 < 4) & ( 42 > 13) |
TRUE |
Dans R, les opérateurs logiques marchent également sur les vecteurs :
x = c(1, 3, 5, 7, 8, 9)x > 3## [1] FALSE FALSE TRUE TRUE TRUE TRUEx < 3## [1] TRUE FALSE FALSE FALSE FALSE FALSEx == 3## [1] FALSE TRUE FALSE FALSE FALSE FALSEx != 3## [1] TRUE FALSE TRUE TRUE TRUE TRUEx == 3 & x != 3## [1] FALSE FALSE FALSE FALSE FALSE FALSEx == 3 | x != 3## [1] TRUE TRUE TRUE TRUE TRUE TRUEC’est très utile pour sélectionner une sous-partie d’un vecteur.
x[x > 3]## [1] 5 7 8 9x[x != 3]## [1] 1 5 7 8 9sum(x > 3)## [1] 4as.numeric(x > 3)## [1] 0 0 1 1 1 1Nous avons vu ici que l’utilisation de la fonction sum() sur un tableau de valeurs logiques Vrai et Faux qui est le résultat de x > 3 donne un résultat numérique : vous venez de compter combien d’éléments de x, la condition > 3 est Vrai. Lors de l’appel à sum(), R est d’abord automatiquement forcé de passer de la logique au numérique où Vrai est 1 et Faux est 0. Cette contrainte de logique à numérique se produit pour la plupart des opérations mathématiques.
# which(condition sur x) renvoie true/false
# chaque indice de x où la condition est vraie
which(x > 3)## [1] 3 4 5 6x [which(x > 3)]## [1] 5 7 8 9max(x)## [1] 9which(x == max(x))## [1] 6which.max(x)## [1] 61.8.2.1 Exercice 2
- Créer un vecteur rempli de 10 nombres tirés de la distribution uniforme (indice : utiliser la fonction
runif) et les stocker dans “x”. - En utilisant un sous-ensemble logique comme ci-dessus, obtenez tous les éléments de
xqui sont plus grands que 0,5, et stockez-les dansy. - en utilisant la fonction
which, stockez les indices de tous les éléments dexqui sont plus grands que 0,5 dansiy. - Vérifiez que
yetx[iy]sont identiques.
1.8.3 Matrices
R peut également être utilisé pour les calculs de matrice. Les matrices ont des lignes et des colonnes contenant un seul type de données. Dans une matrice, l’ordre des lignes et des colonnes est important. (Ce n’est pas le cas des data frames, que nous verrons plus tard).
Les matrices peuvent être créées à l’aide de la fonction matrix.
x = 1:9
x## [1] 1 2 3 4 5 6 7 8 9X = matrix(x, nrow = 3, ncol = 3)
X## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9Remarquez ici que R est sensible à la casse (x contre X).
Par défaut, la fonction matrice remplit vos données dans la matrice colonne par colonne. Mais on peut aussi dire à R de remplir des lignes à la place :
Y = matrix(x, nrow = 3, ncol = 3, byrow = TRUE)
Y## [,1] [,2] [,3]
## [1,] 1 2 3
## [2,] 4 5 6
## [3,] 7 8 9Nous pouvons également créer une matrice d’une dimension spécifique où chaque élément est identique, dans ce cas “0”.
Z = matrix(0, 2, 4)
Z## [,1] [,2] [,3] [,4]
## [1,] 0 0 0 0
## [2,] 0 0 0 0Tout comme les vecteurs, on peut extraire une sous-matrices des crochets, “[]”. Cependant, comme les matrices sont bidimensionnelles, nous devons spécifier à la fois une ligne et une colonne lors du sous-ensemble.
X## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9X[1, 2]## [1] 4Ici, nous avons accédé à l’élément de la première ligne et de la deuxième colonne. Nous avons également pu extraire une ligne ou une colonne entière.
X[1, ]## [1] 1 4 7X[, 2]## [1] 4 5 6Nous pouvons également utiliser des vecteurs pour extraire plus d’une ligne ou d’une colonne à la fois. Dans ce cas, on extrait la première et la troisième colonne de la deuxième ligne :
X [2, c(1, 3)]## [1] 2 8Les matrices peuvent également être créées en combinant des vecteurs sous forme de colonnes, en utilisant cbind, ou en combinant des vecteurs sous forme de lignes, en utilisant rbind.
x = 1:9
rev(x)## [1] 9 8 7 6 5 4 3 2 1rep(1, 9)## [1] 1 1 1 1 1 1 1 1 1rbind(x, rev(x), rep(1, 9))## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
## x 1 2 3 4 5 6 7 8 9
## 9 8 7 6 5 4 3 2 1
## 1 1 1 1 1 1 1 1 1cbind(col_1 = x, col_2 = rev(x), col_3 = rep(1, 9))## col_1 col_2 col_3
## [1,] 1 9 1
## [2,] 2 8 1
## [3,] 3 7 1
## [4,] 4 6 1
## [5,] 5 5 1
## [6,] 6 4 1
## [7,] 7 3 1
## [8,] 8 2 1
## [9,] 9 1 1Lorsque vous utilisez rbind et cbind, vous pouvez spécifier des noms d’“arguments” qui seront utilisés comme noms de colonnes.
R peut alors être utilisé pour effectuer des calculs matriciels
x = 1:9
y = 9:1
X = matrix(x, 3, 3)
Y = matrix(y, 3, 3)
X## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9Y## [,1] [,2] [,3]
## [1,] 9 6 3
## [2,] 8 5 2
## [3,] 7 4 1X + Y## [,1] [,2] [,3]
## [1,] 10 10 10
## [2,] 10 10 10
## [3,] 10 10 10X - Y## [,1] [,2] [,3]
## [1,] -8 -2 4
## [2,] -6 0 6
## [3,] -4 2 8X * Y## [,1] [,2] [,3]
## [1,] 9 24 21
## [2,] 16 25 16
## [3,] 21 24 9X / Y## [,1] [,2] [,3]
## [1,] 0.1111111 0.6666667 2.333333
## [2,] 0.2500000 1.0000000 4.000000
## [3,] 0.4285714 1.5000000 9.000000Notez que X * Y n’est pas une multiplication matricielle. Il s’agit d’une multiplication élément par élément. (Pareil pour X / Y).
La multiplication matricielle utilise l’opérateur %*%. Les autres fonctions matricielles comprennent t() qui donne la transposition d’une matrice et solve() qui renvoie l’inverse d’une matrice carrée si elle est inversible.
X %*% Y## [,1] [,2] [,3]
## [1,] 90 54 18
## [2,] 114 69 24
## [3,] 138 84 30t(X)## [,1] [,2] [,3]
## [1,] 1 2 3
## [2,] 4 5 6
## [3,] 7 8 91.8.3.1 Exercice 3
- Créer un vecteur contenant
1,2,3,4,5appelé v. - Créez une matrice (2,5)
mcontenant les données1,2,3,4,5,6,7,8,9,10. La première ligne doit être “1,2,3,4,5”. - Effectuez la multiplication de la matrice
mparv. Utilisez la commande%*%. Quelle est la dimension de la sortie ? - Pourquoi la commande
v %*% mne fonctionne-t-elle pas ?
1.9 Data Frames
Nous avons déjà vu des vecteurs et des matrices pour le stockage des données lorsque nous avons présenté R. Nous allons maintenant présenter les data frame (bases de données) qui seront la façon la plus courante de stocker et d’interagir avec les données.
example_data = data.frame(x = c(1, 3, 5, 7, 9, 1, 3, 5, 7, 9),
y = c(rep("Hello", 9), "Goodbye"),
z = rep(c(TRUE, FALSE), 5))Contrairement à une matrice, qui peut être considérée comme un vecteur réorganisé en lignes et en colonnes, une data frame n’est pas tenue d’avoir le même type de données pour chaque élément. Une data frame est une liste de vecteurs, et chaque vecteur a un nom. Ainsi, chaque vecteur doit contenir le même type de données, mais les différents vecteurs peuvent stocker des types de données différents. Notez, cependant, que tous les vecteurs doivent avoir la même longueur.
Une data.frame est similaire à un tableur habituel. Il y a des lignes, et des colonnes. Une ligne est généralement considérée comme une observation, et chaque colonne est une certaine variable, ou caractéristique de cette observation.
Regardons la data frame que nous venons de créer
example_data## x y z
## 1 1 Hello TRUE
## 2 3 Hello FALSE
## 3 5 Hello TRUE
## 4 7 Hello FALSE
## 5 9 Hello TRUE
## 6 1 Hello FALSE
## 7 3 Hello TRUE
## 8 5 Hello FALSE
## 9 7 Hello TRUE
## 10 9 Goodbye FALSELà encore, nous accédons à une colonne donnée avec l’opérateur $ :
example_data$x## [1] 1 3 5 7 9 1 3 5 7 9all.equal(length(example_data$x),
length(example_data$y),
length(example_data$z))## [1] TRUEstr(example_data)## 'data.frame': 10 obs. of 3 variables:
## $ x: num 1 3 5 7 9 1 3 5 7 9
## $ y: chr "Hello" "Hello" "Hello" "Hello" ...
## $ z: logi TRUE FALSE TRUE FALSE TRUE FALSE ...nrow(example_data)## [1] 10ncol(example_data)## [1] 3dim(example_data)## [1] 10 3names(example_data)## [1] "x" "y" "z"1.9.1 Travailler sur des data.frames
La fonction data.frame() ci-dessus est une façon de créer une base de données. Nous pouvons également importer des données de différents types de fichiers dans R, ainsi qu’utiliser des données stockées dans des paquets.
Pour recharger ces données dans R, nous utiliserons la fonction read.csv :
example_data_from_disk = read.csv("data/example-data.csv")example_data_from_disk## x y z
## 1 1 Hello TRUE
## 2 3 Hello FALSE
## 3 5 Hello TRUE
## 4 7 Hello FALSE
## 5 9 Hello TRUE
## 6 1 Hello FALSE
## 7 3 Hello TRUE
## 8 5 Hello FALSE
## 9 7 Hello TRUE
## 10 9 Goodbye FALSELorsque nous utilisons des données, il y a généralement trois choses que nous aimerions faire :
- Examiner les données brutes.
- Comprendre les données. (D’où viennent-elles ? Quelles sont les variables ? etc.)
- Visualiser les données.
Pour regarder les données dans un data.frame, nous avons deux commandes utiles : head() et str().
# Nous travaillons avec l'ensemble de données mtcars intégré dans R :
mtcars## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
## Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
## Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
## Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
## Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
## Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
## Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
## Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
## Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
## Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
## Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
## Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
## Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
## Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
## Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
## Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
## Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
## AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
## Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
## Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
## Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
## Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
## Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
## Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
## Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
## Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
## Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2Vous pouvez voir que cela imprime l’intégralité du data.frame à l’écran. La fonction head() affichera les premières n observations de la trame de données.
head(mtcars,n=2)## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21 6 160 110 3.9 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21 6 160 110 3.9 2.875 17.02 0 1 4 4head(mtcars) # défaut## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1La fonction str() affichera la “structure” du cadre de données. Elle affichera le nombre d’ observations et de variables, énumérera les variables, donnera le type de chaque variable, et montrera certains éléments de chaque variable. Ces informations peuvent également être trouvées dans la fenêtre “Environnement” de RStudio.
str(mtcars)## 'data.frame': 32 obs. of 11 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
## $ disp: num 160 160 108 258 360 ...
## $ hp : num 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num 16.5 17 18.6 19.4 17 ...
## $ vs : num 0 0 1 1 0 1 0 1 1 1 ...
## $ am : num 1 1 1 0 0 0 0 0 0 0 ...
## $ gear: num 4 4 4 3 3 3 3 4 4 4 ...
## $ carb: num 4 4 1 1 2 1 4 2 2 4 ...Dans cet base de données, une observation porte sur un modèle particulier de voiture, et les variables décrivent les attributs de la voiture, par exemple son rendement énergétique ou son poids.
Pour en savoir plus sur l’ensemble de données, nous utilisons l’opérateur ? pour extraire la documentation relative aux données.
?mtcarsR dispose d’un certain nombre de fonctions permettant de travailler et d’extraire rapidement des informations de base à partir de cadres de données. Pour obtenir rapidement un vecteur des noms de variables, nous utilisons la fonction names().
names(mtcars)## [1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear"
## [11] "carb"Pour accéder à l’une des variables en tant que vecteur, nous utilisons l’opérateur $.
mtcars$mpg## [1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 10.4
## [16] 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4 15.8 19.7
## [31] 15.0 21.4mtcars$wt## [1] 2.620 2.875 2.320 3.215 3.440 3.460 3.570 3.190 3.150 3.440 3.440 4.070
## [13] 3.730 3.780 5.250 5.424 5.345 2.200 1.615 1.835 2.465 3.520 3.435 3.840
## [25] 3.845 1.935 2.140 1.513 3.170 2.770 3.570 2.780Nous pouvons utiliser les fonctions dim(), nrow() et ncol() pour obtenir des informations sur la dimension de la base de données.
dim(mtcars)## [1] 32 11nrow(mtcars)## [1] 32ncol(mtcars)## [1] 11Ici nrow() est aussi le nombre d’observations, qui dans la plupart des cas est la taille de l’échantillon.
La sélection de sous-partie de la base de données peut fonctionner comme pour les matrices en utilisant des crochets, [ , ]. Ici, nous trouvons des véhicules dont le mpg est supérieur à 25 miles par gallon et nous n’affichons que les colonnes cyl, disp et wt.
# mpg [condition ligne, condition colonne]
mtcars [mtcars$mpg > 20, c("cyl", "disp", "wt")]## cyl disp wt
## Mazda RX4 6 160.0 2.620
## Mazda RX4 Wag 6 160.0 2.875
## Datsun 710 4 108.0 2.320
## Hornet 4 Drive 6 258.0 3.215
## Merc 240D 4 146.7 3.190
## Merc 230 4 140.8 3.150
## Fiat 128 4 78.7 2.200
## Honda Civic 4 75.7 1.615
## Toyota Corolla 4 71.1 1.835
## Toyota Corona 4 120.1 2.465
## Fiat X1-9 4 79.0 1.935
## Porsche 914-2 4 120.3 2.140
## Lotus Europa 4 95.1 1.513
## Volvo 142E 4 121.0 2.780Une alternative serait d’utiliser la fonction subset(), qui a une syntaxe beaucoup plus lisible.
subset(mtcars, subset = mpg > 25, select = c("cyl", "disp", "wt"))1.9.1.1 Exercice 5
- Combien d’observations y a-t-il dans
mtcars? - Combien de variables ?
- Quelle est la valeur moyenne de
mpg? - Quelle est la valeur moyenne de
mpgpour les voitures de plus de 4 cylindres, c’est-à-dire aveccyl>4?
1.10 Les bases de la programmation en R
Dans cette section, nous illustrons quelques concepts généraux liés à la programmation en R.
1.10.1 Variables
Nous avons déjà rencontré le terme de “variable”" à plusieurs reprises, mais principalement dans le contexte d’une colonne d’une data.frame. En programmation, une variable désigne un “objet”. Une autre façon de le dire est qu’une variable est un nom ou une étiquette pour quelque chose :
x <- 1
y <- "roses"
z <- function(x){sqrt(x)}Ici, x fait référence à la valeur 1, y contient la chaîne de caractères “roses”, et z est le nom d’une fonction qui calcule \(\sqrt{x}\). Remarquez que l’argument x de la fonction est différent du x que nous venons de définir. Il est local à la fonction et n’affecte pas le x défini à lextérieur de la fonction :
x## [1] 1z(9)## [1] 31.10.2 Contrôle du flux, conditions “si, alors”
Le contrôle de flux d’execution concerne les moyens par lesquels vous pouvez adapter votre code à différentes circonstances. Si une “condition” est TRUE, votre programme fera une chose, et sinon une autre. C’est ce que l’on appelle une déclaration “if/else”. Dans R, la syntaxe if/else est :
if (condition = TRUE) {
un peu de code R
} else {
un autre code R
}Par exemple,
x <- 1
y <- 3
if (x > y) { # test si x > y
# si VRAI
z <- x * y
print("x est plus grand que y")
} else {
# si FAUX
z <- x + 5 * y
print("x est inférieur ou égal à y")
}## [1] "x est inférieur ou égal à y"z## [1] 161.10.3 Boucles
Les boucles sont un élément de programmation très important. Comme son nom l’indique, dans une boucle, la programmation passe en boucle de façon répétée sur un ensemble d’instructions, jusqu’à ce qu’une condition lui dise de s’arrêter. Par ailleurs, le programme peut savoir combien d’étapes il a déjà effectuées - ce qui peut être important à savoir pour de nombreux algorithmes. La syntaxe d’une boucle for (il en existe d’autres) est
for (ix in 1:10){ # ne doit pas nécessairement être 1:10 !
# corps de la boucle : est exécuté à chaque fois
# la valeur de ix change à chaque itération
}Par exemple, considérons cette simple boucle for, qui va simplement imprimer la valeur de l’itérateur (appelé i dans notre cas) à l’écran :
for (i in 1:5){
print(i)
}## [1] 1
## [1] 2
## [1] 3
## [1] 4
## [1] 5Remarquez qu’au lieu de “1:5”, nous pourrions avoir n’importe quelle sorte de collection d’éléments sur lesquels itérer :
for (i in c("mangues", "bananes", "pommes")){
print(paste("J'aime les",i)) # la fonction de collage "paste" colle les chaînes de caractères
}## [1] "J'aime les mangues"
## [1] "J'aime les bananes"
## [1] "J'aime les pommes"Nous pouvons "aussi souvent également utiliser des boucles emboîtées, qui sont exactement ce que leur nom suggère :
for (i in 2:3){
# premier niveau : pour chaque i
for (j in c("mangues", "bananes", "pommes")){
# deuxième niveau : pour chaque j
print(paste("Puis-je avoir",i,j, "s'il vous plaît ?"))
}
}## [1] "Puis-je avoir 2 mangues s'il vous plaît ?"
## [1] "Puis-je avoir 2 bananes s'il vous plaît ?"
## [1] "Puis-je avoir 2 pommes s'il vous plaît ?"
## [1] "Puis-je avoir 3 mangues s'il vous plaît ?"
## [1] "Puis-je avoir 3 bananes s'il vous plaît ?"
## [1] "Puis-je avoir 3 pommes s'il vous plaît ?"Ce qu’il est important de remarquer ici, c’est que vous pouvez faire des calculs avec les itérateurs tout en restant dans une boucle.
for (i in 1:4) {
for (j in 1:4) {
ifoisj <- i*j
print(paste(i,"fois",j,"=",ifoisj))
}
}## [1] "1 fois 1 = 1"
## [1] "1 fois 2 = 2"
## [1] "1 fois 3 = 3"
## [1] "1 fois 4 = 4"
## [1] "2 fois 1 = 2"
## [1] "2 fois 2 = 4"
## [1] "2 fois 3 = 6"
## [1] "2 fois 4 = 8"
## [1] "3 fois 1 = 3"
## [1] "3 fois 2 = 6"
## [1] "3 fois 3 = 9"
## [1] "3 fois 4 = 12"
## [1] "4 fois 1 = 4"
## [1] "4 fois 2 = 8"
## [1] "4 fois 3 = 12"
## [1] "4 fois 4 = 16"Les Primers de rstudio.cloud contiennent un tutoriel sur les boucles qui va au delà de cette brève introduction, et introduite de nouveaux outils
1.10.4 Fonctions
Jusqu’à présent, nous avons utilisé des fonctions, mais nous n’avons pas vraiment discuté de certains de leurs détails. Une fonction est un ensemble d’instructions que R exécute pour nous, un peu comme celles qu’on écrit dans un script. L’avantage est que les fonctions sont beaucoup plus flexibles que les scripts, car elles peuvent dépendre d’arguments en entrée, qui modifient le comportement de la fonction. Voici comment définir une fonction :
nom_de_la_fonction <- function(arg1,arg2=valeur_par_défaut){
# corps de la fonction
# faire des choses avec arg1 et arg2
# vous pouvez avoir un nombre illimité d'arguments, avec ou sans défaut
# Toute commande "R" valide peut être incluse ici
# la dernière ligne est renvoyée comme résultat de la fonction
}Et voici un exemple trivial de définition d’une fonction :
bonjour <- function(votre_nom = "Lord Vader"){
paste("Bienvenue,",votre_nom)
# nous pourrions aussi écrire :
# return(paste("Bienvenue,",votre_nom))
}
# nous appelons la fonction en tapant son argument entre parenthèses
bonjour()## [1] "Bienvenue, Lord Vader"Vous voyez qu’en ne spécifiant pas l’argument votre_nom, R utilise à la valeur par défaut donnée. Essayez avec votre propre nom maintenant !
Le simple fait de taper le nom de la fonction (sans parenthèses) nous renvoie sa définition, ce qui est parfois pratique :
bonjour## function(votre_nom = "Lord Vader"){
## paste("Bienvenue,",votre_nom)
## # nous pourrions aussi écrire :
## # return(paste("Bienvenue,",votre_nom))
## }Il est instructif de considérer qu’avant de définir la fonction “bonjour” ci-dessus, R ne savait pas quoi faire, si vous aviez appelé bonjour. La fonction n’existait pas ! En ce sens, nous avons appris à R un nouveau truc. Cette fonction permettant de créer de nouvelles capacités en plus d’un langage de base est l’une des caractéristiques les plus puissantes des langages de programmation. En général, il est bon de diviser votre code en plusieurs petites fonctions, plutôt qu’en un long fichier de script. Cela rend votre code plus lisible, et il est plus facile de repérer les erreurs.
Les Primers de rstudio.cloud contiennent un tutoriel sur les fonctions qui vous permettra d’aller plus loin sur ce thème.
1.10.4.1 Exercice 6
- Écrivez une boucle qui compte à rebours de 10 à 1, en imprimant la valeur de l’itérateur à l’écran.
- Modifiez cette boucle pour écrire “plus que i itérations” où “i” est l’itérateur
- Modifiez cette boucle de manière à ce que chaque itération dure environ une seconde. Vous pouvez y parvenir en ajoutant la commande
Sys.sleep(1)sous la ligne qui affiche “plus que i itérations”.